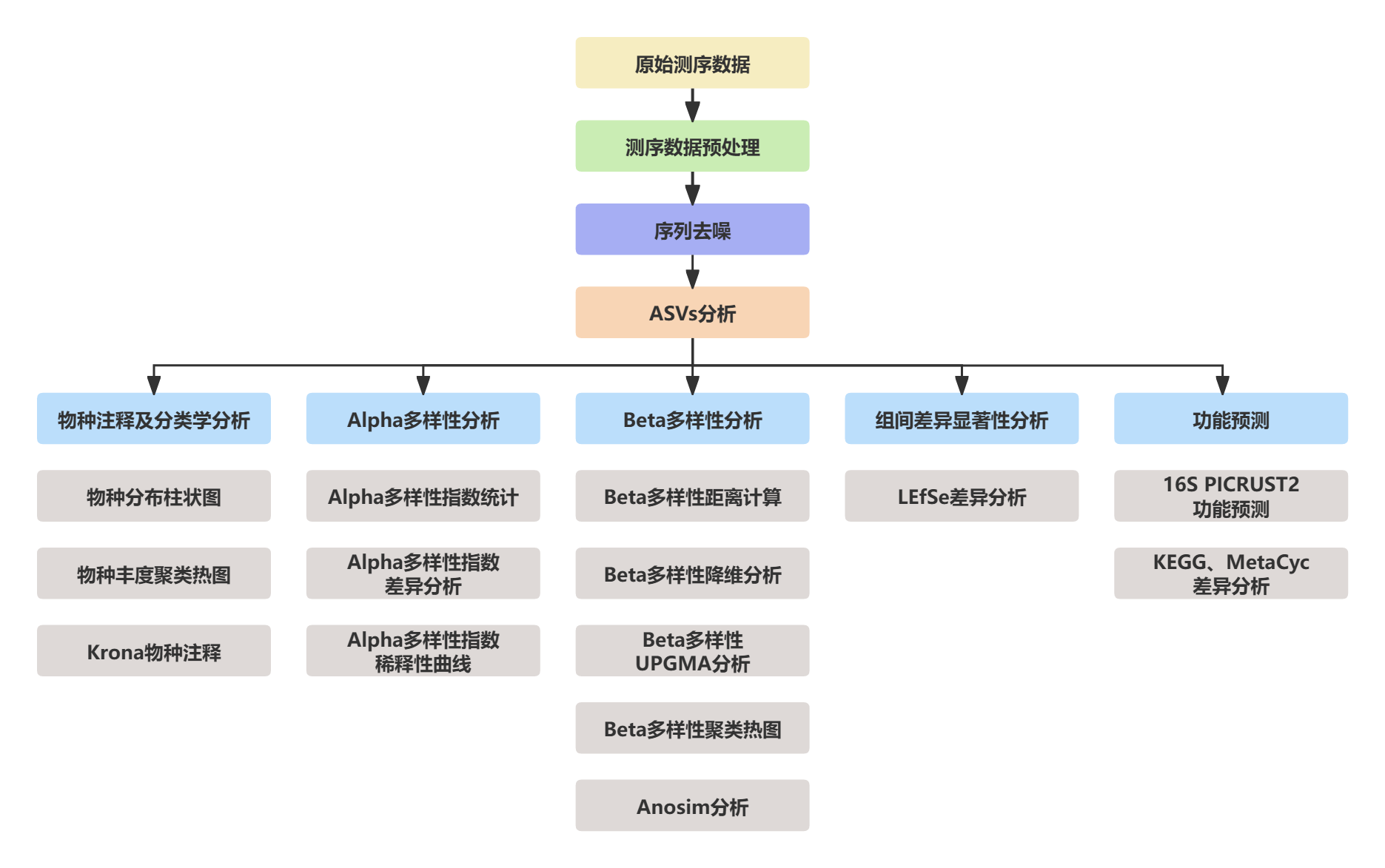
Meta扩增子测序的生信分析首先对测序原始数据进行拼接、过滤、质控,得到有效数据。然后基于有效数据进行OTUs(Operational Taxonomic Units )聚类和物种分类分析。根据OTUs聚类结果,一方面对每个OTU的代表序列做物种注释,得到对应的物种信息和基于物种的丰度分布情况。同时,对OTUs进行丰度、Alpha多样性计算等分析,以得到样本内物种丰富度和均匀度信息、不同样本或分组间的共有和特有OTUs信息等。另一方面,可以对OTUs进行不同样本或组别间群落结构差异的探究。同时,也可结合环境因素进行多样性指数与环境因子的相关性分析,得到显著影响组间群落变化的环境影响因子。
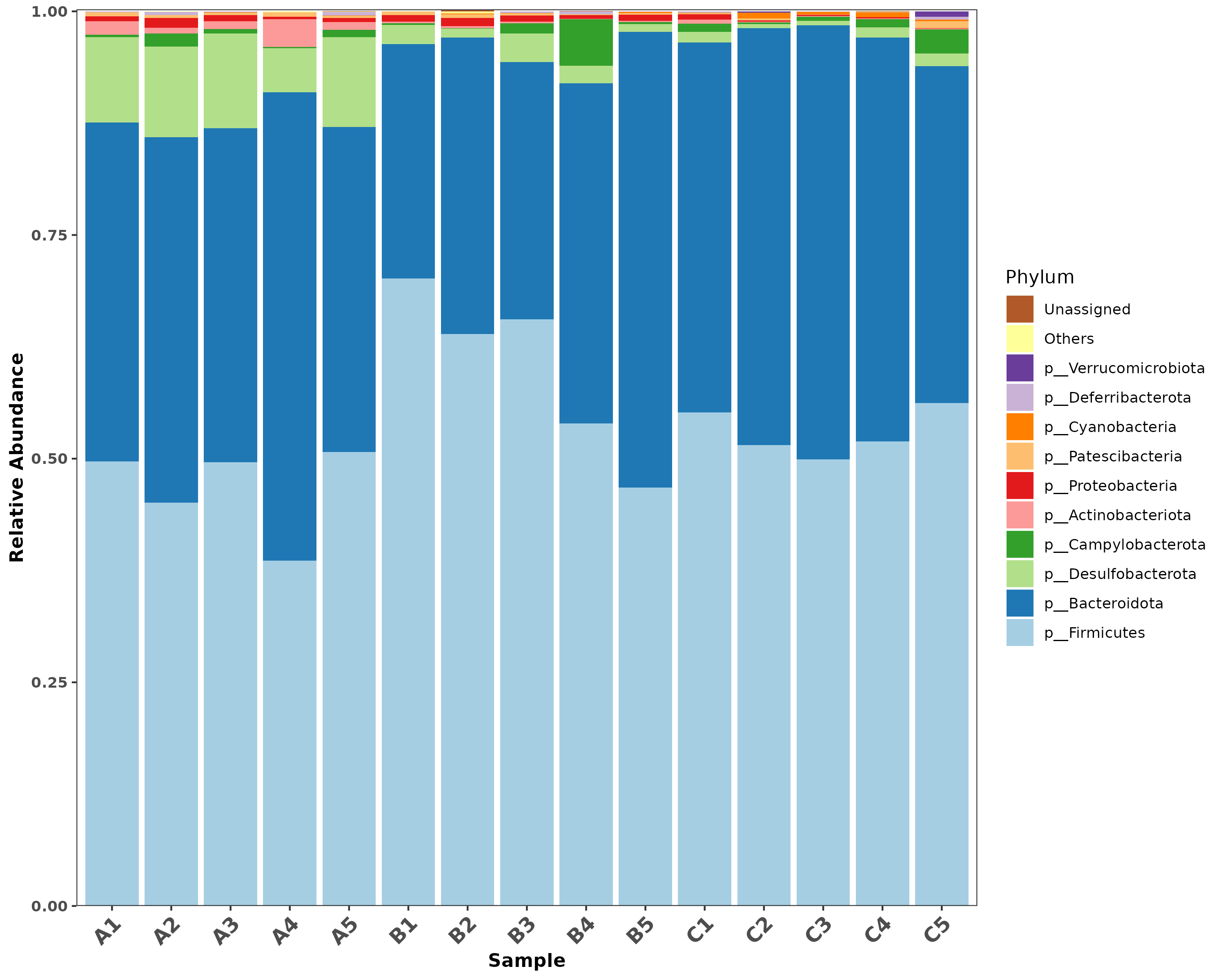
物种丰度柱形图
根据物种注释结果,选取每个样品在各分类水平(Phylum、Class、Order、Family、Genus)上最大丰度排名前10的物种,生成物种相对丰度柱形累加图,以便直观查看各样品在不同分类水平上,相对丰度较高的物种及其比例。
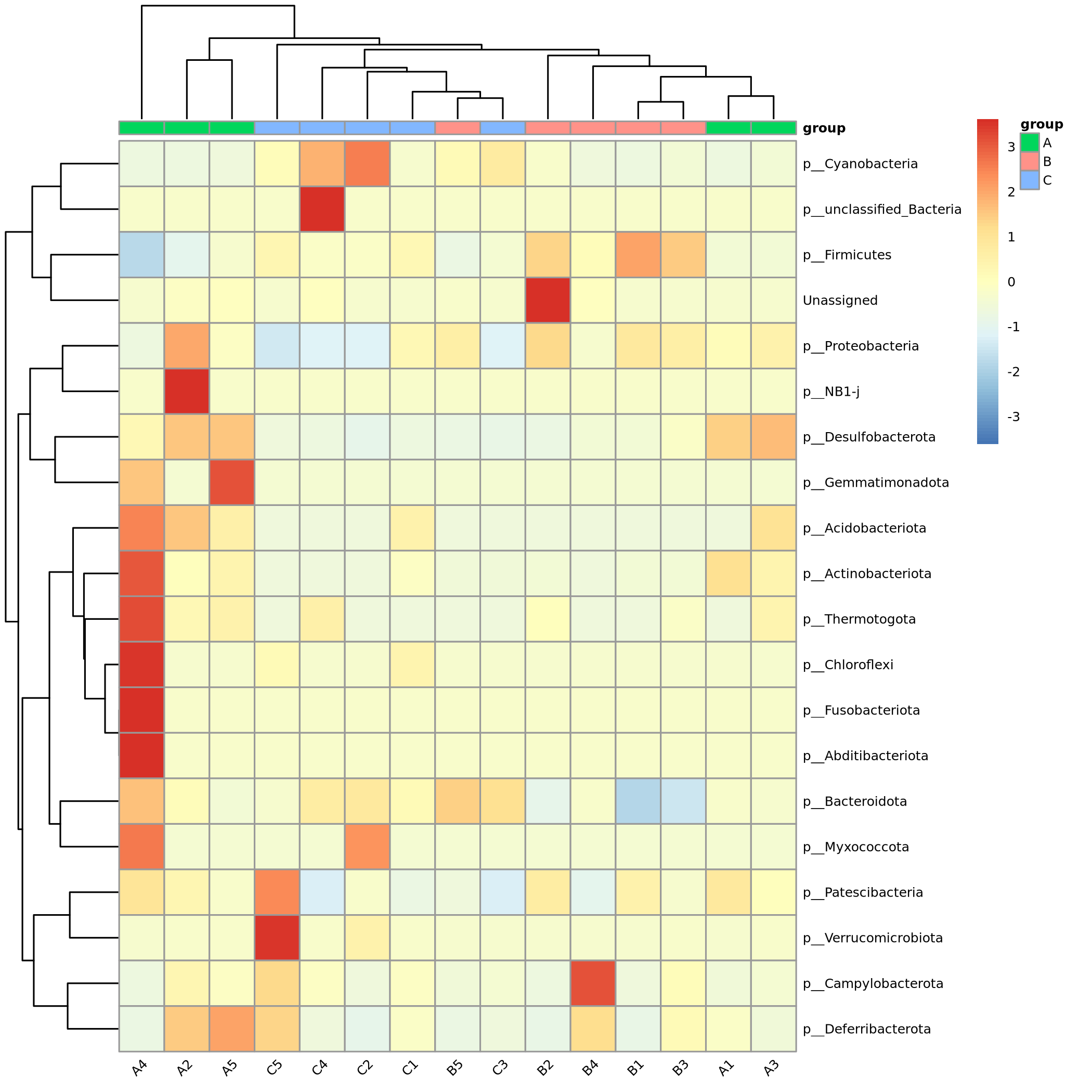
物种丰度聚类热图
根据所有样品在属水平的物种注释及丰度信息,选取丰度排名前35的属,根据其在每个样品中的丰度信息,从物种和样品两个层面进行聚类,绘制成热图,便于发现哪些物种在哪些样品中聚集较多或含量较低。
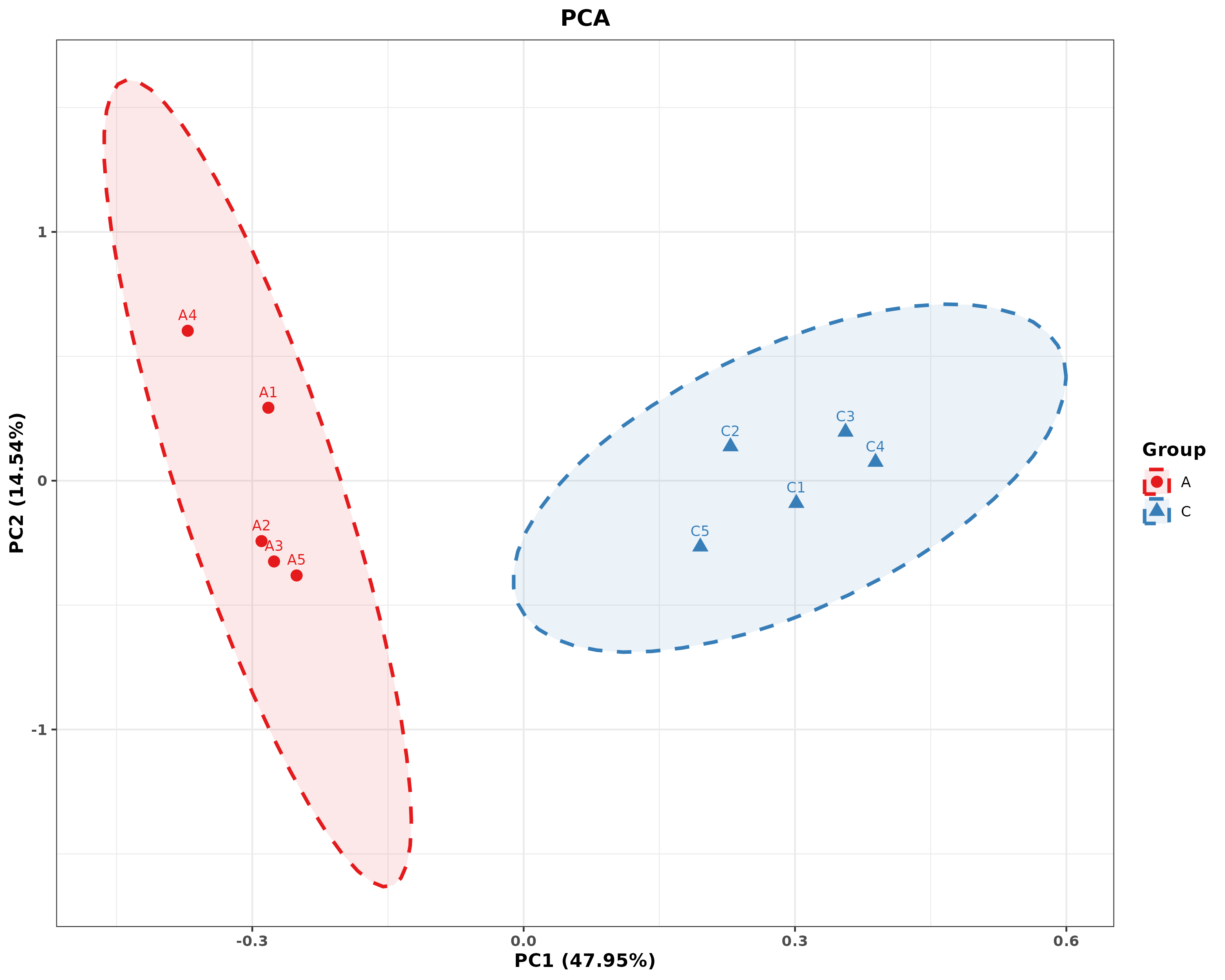
主成分分析
主成分分析(Principal Component Analysis,PCA)是一种应用方差分解方法,对多维数据进行降维,从而提取出数据中最主要的元素和结构。应用PCA分析,能够提取出最大程度反映样品间差异的两个坐标轴,从而将多维数据的差异反映在二维坐标图上,进而揭示复杂数据背景下的简单规律。如果样品的群落组成越相似,则它们在PCA图中的距离越接近。
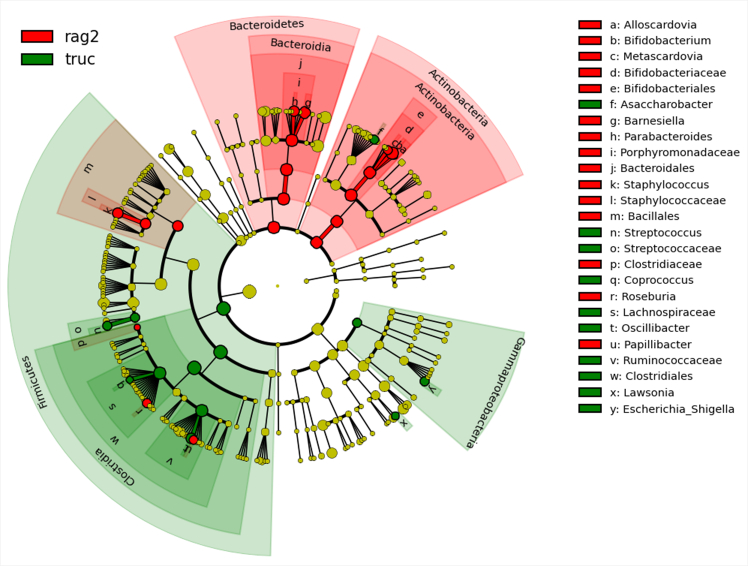
LEfSe分析
LEfSe(LDA Effect Size)是一种用于发现高维生物标识和揭示基因组特征的软件,用于寻找组间差异显著的物种。包括基因,代谢和分类,用于区别两个或两个以上生物类群。该算法强调的是统计意义和生物相关性,让研究人员能够识别不同丰度的特征以及相关联的类别,以寻找具有统计学差异的Biomarker。
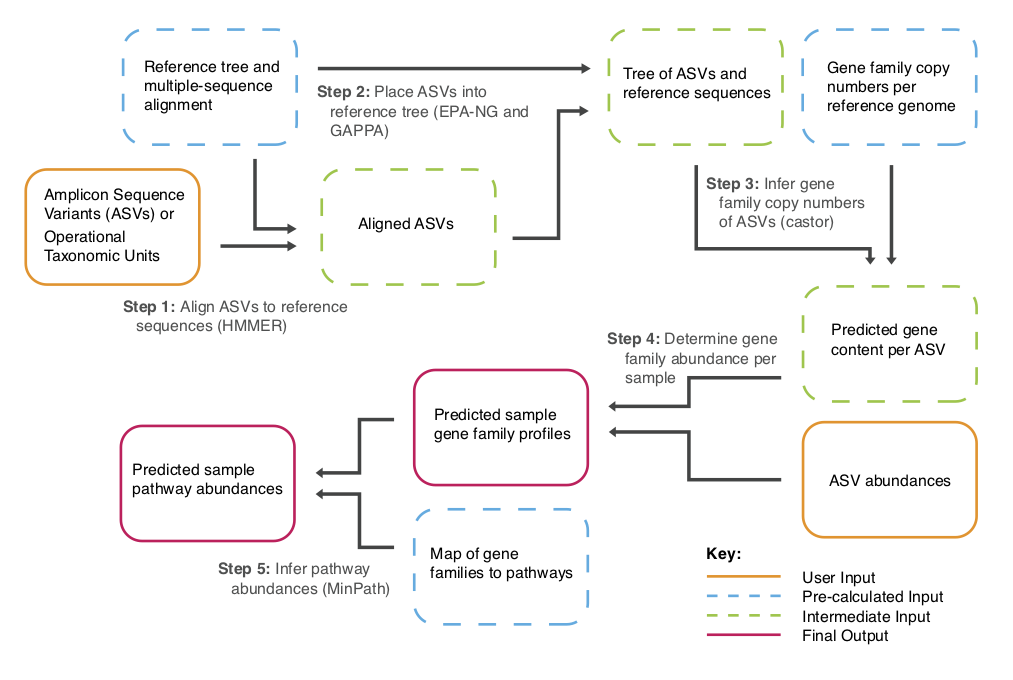
PICRUSt2功能预测
PICRUSt2(Phylogenetic Investigation of Communities by Reconstruction of Unobserved States)[21]是一款基于样本中的标记基因序列丰度来预测样本功能丰度的软件。这里的功能是指基因家族,如KEGG同源基因、EC酶分类号等,其原理如下图所示:

 0571-83693553
0571-83693553 cw@cwmda.com
cw@cwmda.com 浙江省 杭州市 萧山区 金二路617号 信息港六期10幢
浙江省 杭州市 萧山区 金二路617号 信息港六期10幢